 |
 |
|
|
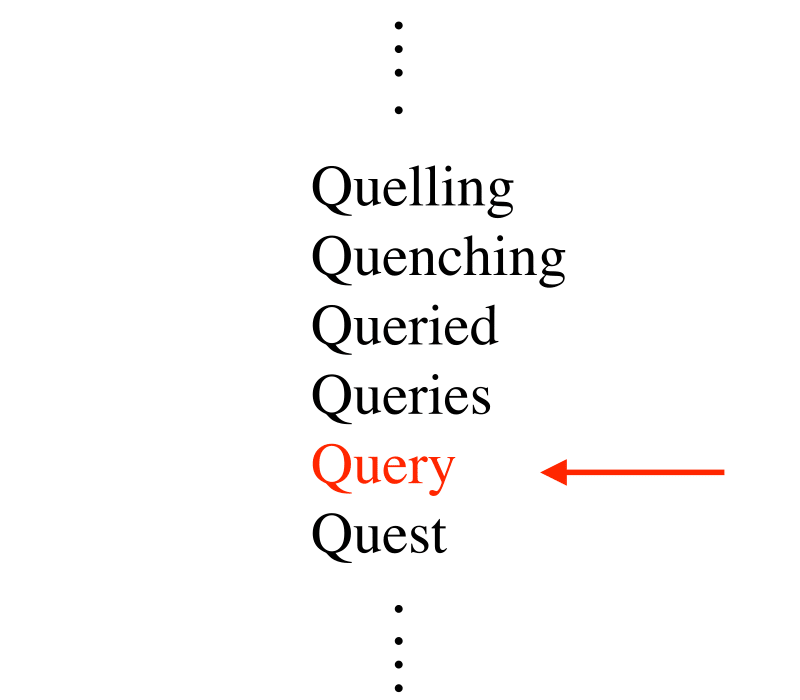
Input Description: A set of \(n\) records, each identified by one or more key fields.
Problem: Build and maintain a data structure to efficiently locate, insert, or delete the record associated with any query key \(q\).
Excerpt from The Algorithm Design Manual: The abstract data type ``dictionary'' is one of the most important structures in computer science. Dozens of different data structures have been proposed for implementing dictionaries including hash tables, skip lists, and balanced/unbalanced binary search trees -- so choosing the right one can be tricky. Depending on the application, it is also a decision that can significantly impact performance. In practice, it is more important to avoid using a bad data structure than to identify the single best option available.
An essential piece of advice is to carefully isolate the implementation of the dictionary data structure from its interface. Use explicit calls to subroutines that initialize, search, and modify the data structure, rather than embedding them within the code. This leads to a much cleaner program, but it also makes it easy to try different dictionary implementations to see how they impact performance. Do not obsess about the cost of the procedure call overhead inherent in such an abstraction. If your application is so time-critical that such overhead can impact performance, then it is even more essential that you be able to easily experiment with different implementations of your dictionary.
  Priority Queues |
 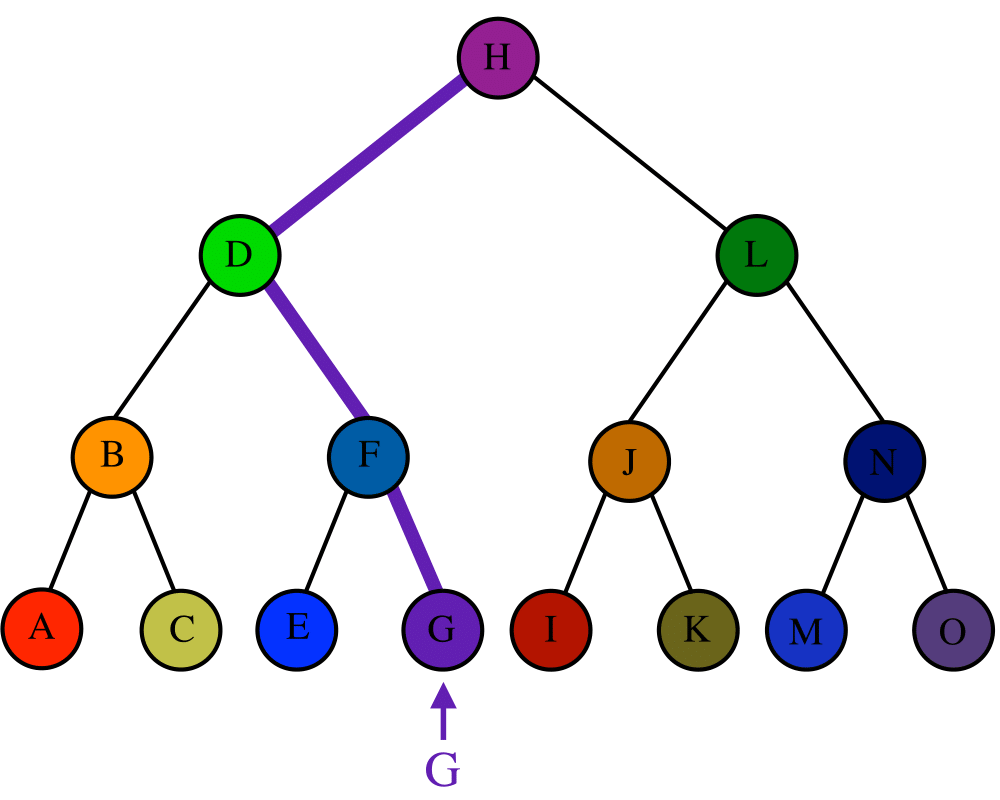 Searching |
  Sorting |
As an Amazon affiliate, I earn from qualifying purchases if you buy from links on this website.
.jpg) Data Structures and Algorithm Analysis in C++ (3rd Edition) by Mark Allen Weiss
Data Structures and Algorithm Analysis in C++ (3rd Edition) by Mark Allen Weiss Handbook of Data Structures and Applications by D. Mehta and S. Sahni
Handbook of Data Structures and Applications by D. Mehta and S. Sahni Data Structures, Near Neighbor Searches, and Methodology: Fifth and Sixth Dimacs Implementation Challenges by Michael H. Goldwasser and Catherine C. McGeoch
Data Structures, Near Neighbor Searches, and Methodology: Fifth and Sixth Dimacs Implementation Challenges by Michael H. Goldwasser and Catherine C. McGeoch Algorithms in C++: Fundamentals, Data Structures, Sorting, Searching by Robert Sedgewick
Algorithms in C++: Fundamentals, Data Structures, Sorting, Searching by Robert Sedgewick The Art of Computer Programming: Fundamental Algorithms by Donald Knuth
The Art of Computer Programming: Fundamental Algorithms by Donald Knuth